Improving SEO without knowing where to start
by Alexis Degryse published on
Summary
Introduction ↑
Colleagues sometimes ask me: “Hey Alex, I would like to learn a bit about search engine optimisation (SEO) but I don't really know where to start. Do you have tips for me?”. Well, it's not surprising: like accessibility, sustainability and environment, or performance, SEO is a big topic.
I usually answer: “It's awesome that you want to dig into this. SEO is also a significant part of UX, and more globally of web quality assurance. Listen, I'm not a SEO expert but I know a solid start: these are the Opquast rules. If you apply them carefully, you will do better than most other websites.”
In this article, first I would like to describe shortly what SEO means, then present what Opquast is, and finally explain the benefits of some Opquast's SEO rules.
Disclaimer: Opquast is a society. I am neither an employee nor an affiliate.
What is SEO ? ↑
SEO stands for Search Engine Optimisation. It comprises improving the visibility of a page, a site, an application in search engine results pages (abbreviated SERP). Being positioned on the first page is obviously a good thing for the owner of a site, but it's also about helping search and indexing tools to extract content efficiently, helping users find your content, improving the visual and vocal reproduction of search results to users.
Many people say “SEO is a marathon, not a sprint”, and they're right. As Frederick O’Brien wrote in his article A Smashing Guide To The World Of Search Engine Optimization on Smashing Magazine:
Implementing best practice can produce immediate results, but long-term performance requires long-term maintenance.
We could also establish that SEO is about getting as close as possible to the “requirements” of Google and its Page Rank calculation algorithm, but I suggest you don't bother too much with that, especially since the statements of SEO agencies, official communication from Google, and engineers at Google can sometimes contradict each other.
SEO is cool because it makes developers and designers care about web quality (I personally prefer this term rather than UX). Long ago, SEO strategies were mostly about accumulating backlinks (regardless of the quality) and putting important keywords everywhere.
Things have fortunately changed. Today, search engines will favor sites which care about users:
- Content:
- both in style (spelling, grammar, freshness of content, consistency between titles, content and keywords)
- and substance (relevance, reliability, veracity, completeness)
- Netlinking: quality backlinks
- Performance: “Hello Core Web Vitals”[1]
- Responsiveness: today, more than half of search queries now come from mobile devices
- Semantics: a well-structured and intelligently designed site in HTML is easier to browse by an indexing robot, informations are extracted in a clearer way
- Accessiblity: (although it's not a direct ranking factor): always a good thing to remember, accessibility means that people with disabilities can perceive, understand, navigate, contribute and interact with the web2
- Security: HTTPS, protection from XSS, tracking, info leaks, etc.
Web quality with Opquast ↑
Opquast is a French pioneering company in web quality assurance, focused on “Making the web better”. Opquast is well-known in France for having created The Web Quality Assurance Checklist (under open CC-BY-SA license, available in English, French and Spanish), a list of 240 rules to improve your sites and take better care of your users. Opquast ensures that each of these 240 rules is written in such a way that they are:
- Transversal: they are understandable by everyone (developer, designer, dev ops, community manager, marketing manager, sales, web editor, project manager, etc.)
- Universal: they are the subject of consensus in consultation with a broad community of experts, agencies, companies and higher education
- Sustainable: they are made to last over time
- easily Verifiable
- Useful for users
- Realistic
These rules cover a wide range of topics (security, links, personal information, performance, navigation, images, forms, newsletters, structure, e-commerce, etc.).
Some examples:
- Rule n° 39 - The period of validity and conditions of special offers and promotions are indicated
- Rule n° 171 - It is possible to unsubscribe from newsletters from the website
- Rule n° 16 - Account creation is possible without the need to use a third-party identification system.
Among these 240 rules, 37 are SEO-related (you'll notice that some rules cover several topics at once) and I want to show you some of them.
SEO-related Opquast rules ↑
Describe information about the page
Rule n° 3 - Each page’s source code contains metadata that describes the content.
Thanks to meta tags, search engines can provide a short description of the page to users in search result pages (SERP). (Besides, it can be automatically displayed when you share a link on social networks).
<meta name="description" content="information about the page here">If you omit it, you let search engines choose the description for you (and that's rarely a good thing).
Identify the site and its content
Rule n° 97 - Each page provides a title that enables one to identify the website.
Rule n° 98 - Each page provides a title that enables one to identify its content.
Text in the title element is really important, it's used everywhere: tabs, bookmarks, favorites, homescreen phone, screen readers, share preview, social media. And in SERP obviously.

In the title element from the "Customer Support" page of the Burger King website, the text is just "Burger King". The site is identified but not the content (Notice how it fails rule n° 3).
Alternative text
Rule n° 111 - Each decorative image has an appropriate text alternative.
If an image doesn't provide any important information for the good understanding of the content, simply add alt="" to it. Otherwise, you let this sort thing happen:

Rule n° 113 - Each information-carrying image has an appropriate text alternative.
When an image contains textual and/or visual information useful to understanding the content, it must be described in the alt attribute. As you saw in the example of rule n° 97, alternative texts are also taken into account.
<div class="f-incentiveBox__content">
<img src="/brutX-logo-v2.png">
<b>1 MOIS OFFERT</b> puis 4,99€/mois
</div>This piece of HTML is from a product page on fnac.com. The product is on sale with a one-month free offer at a video streaming platform (BrutX). But if you are an indexing robot (or a screen reader user), you wouldn't know because the alt attribute is missing.
Links
Rule n° 112 - Each image link has an appropriate text alternative.
Users hate unlabeled links. Indexing robots too. They will find this content irrelevant and hard to reference.
<a href="/actualite-sup_veto_formation_asv" target="_blank">
<img src="/imageDiplomeo032022.jpg" alt="">
</a>This piece of HTML is from supveto.com. There is an alt attribute, but it's empty and it doesn't provide the link with an accessible name.
Rule n° 147 - All links internal to the website are valid.
I said indexing robots hate unlabeled links; they hate broken links even more. You might not be able to check external links regularly but regarding internal links, try to set up a routine (automated or not) to check their validity.
A bit of semantics
Rule n° 125 - Each page’s source code indicates the content’s main language.
Another easy way to help indexing robots crawl your content is to fill the lang attribute at the root of the document. Because the natural language of a page isn't always identifiable by tools as screen readers, translation tools, indexing robots, etc.
Example for English:
<html lang="en">You can also indicate a temporary change of language inside content:
<html lang="en">
...
<body>
...
<ul>
...
<li>
<a href="path/to/german/content">
<span lang="de">Deutsch</span> (German)
</a>
</li>
<li>
<a href="path/to/danish/content">
<span lang="da">Dansk</span> (Danish)
</a>
</li>
...
</ul>
</body>
</html>Available values are listed on iana.org.
Rule n° 224 - The date of publication or update of the contents is made available in a programmatic form.
I always recommend showing a publication date on content pages. It allows users to put what they read into context (reading an article from 2007 is not the same as reading an article from 2022).
Indexing robots also appreciate having a date, even more when it's explicit. See some examples below:
Updated on <time datetime="2022-06-12">June 12</time>.
Published on <time datetime="2022-09-27">Sep 27, 2022</time>.
The event starts at <time datetime="20:00">8pm</time>.More examples about this format on developer.mozilla.org and infos on html.spec.whatwg.org.
Rule n° 227 - Each page’s content is organized according to a hierarchical structure of headings and sub-headings.
Headings are a truly big topic. They are very helpful for users and assistive technologies to apprehend the structure of a page and navigate it. They are also useful for indexing tools because they help them understand what should be considered important. Thus:
- don't use too long headings.
- don't skip levels (for example, an
h3must not be followed by anh5orh6). - don't use
hxonly for visual purposes (use CSS instead) - don't use too many headings (if everything is important, nothing is).
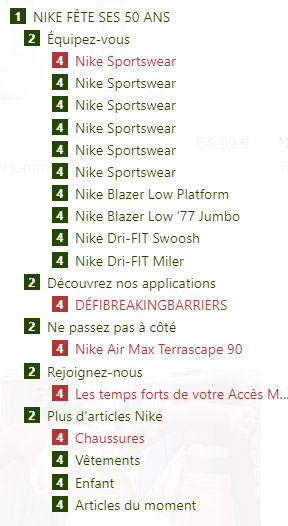
The structure would benefit from being clearer and more relevant here, especially the multiple headings “Nike Sportwear” are really confusing.
Indexing robots crawl PDF documents as well. You can access a PDF document directly from a SERP.
Rule n° 233 - The text of internal PDF documents can be selected.
Not being selectable means that the content of the PDF cannot be crawled (in addition to not being able to be copied, searchable, clickable, translatable, vocalizable). Scanned document are a pain for users, for indexing robots too.
Rule n° 234 - Internal PDF documents are given a structure based on titles.
This one is a variant of the rule 227. The same benefits apply here as well. Use the formatting tools (Heading 1, Heading 2, etc.) in your software to generate a structured PDF.
Conclusion ↑
That's it! There are other rules. I invite you to dig more into these (writing about every rule would have made this article way too long). Remember: your approach towards SEO has to be "user first" (search engines will reward you for that). Think this way about SEO, but also for accessibility, performance, privacy, responsive design, eco-conception. Imagine all these themes cohabiting and interacting in a virtuous circle.
Find out more
- Opquast - The Web Quality Assurance Checklist
- Google - Get started with Search: a developer's guide
- Google - Search Engine Optimization (SEO) Starter Guide
- Smashing Magazine - A Smashing Guide To The World Of Search Engine Optimization
Footnotes
- Web Vitals is an initiative by Google to provide unified guidance for quality signals that are essential to delivering a great user experience on the web. See web.dev/vitals. ↑
- This definition is from the Web Accessiblity Initiative. More explanation at w3.org/WAI. ↑
About Alexis Degryse
My name is Alexis Degryse.
I’m an experienced UI developer / Accessibility referent, and work at INEAT, based in Lille, France as Tech Lead. I’m in charge of technical support of all interface-related topics (semantics, accessibility, ergonomics, SEO, responsive, animations, etc.). I sometimes do some other stuff like job interviews, teaching and career management.
I’m really into HTML & CSS. Those languages, which are - as I like to say - easy to learn but hard to master, are my daily tools and constitute the main thread of my self-learning.
I do my best to keep my skills updated in order to always provide the most suitable solutions for any project and give best advices about the implications and feasibility of UI ideas.
Website: alexis-degryse.com
Twitter: @twogrey
Mastodon: @twogrey@h4.io
LinkedIn: alexis-degryse
CodePen: twogrey
GitHub: twogrey